Today I’ve found myself mainly thinking about the interaction between Frobenius and the filtration on crystalline cohomology, referring to Mazur’s classic paper http://projecteuclid.org/download/pdf_1/euclid.bams/1183533965 as well as Ogus’ paper on “Griffiths Transversality in Crystalline Cohomology” and thought I would record a summary here before I forget everything. Of course, both of these papers are from the 1970s, so if there has been any significant advance or later examples of interest that any readers know of I’d be extremely interested to hear.
Firstly the setup. Let 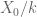 be a smooth projective variety over a perfect field of characteristic
be a smooth projective variety over a perfect field of characteristic  , and let us also suppose we have a smooth proper lift
, and let us also suppose we have a smooth proper lift  . We can form the crystalline cohomology and have comparisons
. We can form the crystalline cohomology and have comparisons 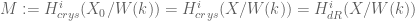 . Let us assume these are free modules and in fact also that the Hodge cohomology groups
. Let us assume these are free modules and in fact also that the Hodge cohomology groups 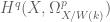 are free. Then we have the further relation that
are free. Then we have the further relation that 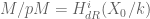 .
.
What structures are in play? Algebraic de Rham cohomology comes with a Hodge filtration  (which depends on the lift
(which depends on the lift  , though of course mod it does not), and crystalline cohomology is equipped with a semilinear Frobenius
, though of course mod it does not), and crystalline cohomology is equipped with a semilinear Frobenius  (which does not depend on the lift).
(which does not depend on the lift).
The fundamental relationship between these two structures is given by a theorem of Mazur, which implies under the freeness assumptions we have made that the Frobenius determines the mod Hodge filtration.
Theorem (Mazur): The reduction mod of 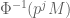 is precisely the reduction of
is precisely the reduction of 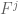 .
.
(Note for the statement that Frobenius induces an isomorphism 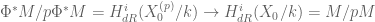 preserving the Hodge filtration.)
preserving the Hodge filtration.)
One immediate consequence of this is the conjecture of Katz relating the slopes of Frobenius to the shape of the Hodge filtration.
Corollary: For the crystalline cohomology of 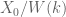 , the Newton polygon lies above the Hodge polygon.
, the Newton polygon lies above the Hodge polygon.
We do not explain what this means here, except to remark that Mazur’s theorem allows you to find bases in which the matrix for 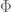 has columns divisible by powers of of widths given by the Hodge numbers. The statement, which is about relating these numbers to valuations of eigenvalues, is then just an easy result in linear algebra.
has columns divisible by powers of of widths given by the Hodge numbers. The statement, which is about relating these numbers to valuations of eigenvalues, is then just an easy result in linear algebra.
The next obvious question is what can we say about the Hodge filtration 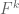 coming from our smooth lift? The above result tells us that
coming from our smooth lift? The above result tells us that
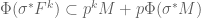 .
.
Mazur was also able to prove that  , where
, where 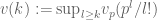 .
.
Question (Mazur): Is it in fact the case that 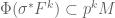 ? If so, we say
? If so, we say  is strongly divisible, and this statement is equivalent to Frobenius inducing an isomorphism
is strongly divisible, and this statement is equivalent to Frobenius inducing an isomorphism 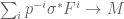 .
.
Note that whenever the Hodge filtration has length shorter than , this is immediate from Mazur’s second inequality, since 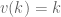 in this case for all nonempty pieces of filtration. For example, for the cohomology of a curve or
in this case for all nonempty pieces of filtration. For example, for the cohomology of a curve or  of an abelian variety we do get something strongly divisible.
of an abelian variety we do get something strongly divisible.
The reason for the distance between Mazur’s estimate and the notion of strong divisibility is the phenomenon of Griffiths transversality, which was investigated by Ogus in the crystalline context following Griffiths’ work in classical Hodge theory.
Classically suppose you have a variety ![X/\mathbb{C}[[t]]](https://s0.wp.com/latex.php?latex=X%2F%5Cmathbb%7BC%7D%5B%5Bt%5D%5D&bg=ffffff&fg=545454&s=0&c=20201002) and you want to study its de Rham cohomology. Using the Gauss-Manin connection, one can identify the cohomology group itself with the cohomology of the constant family
and you want to study its de Rham cohomology. Using the Gauss-Manin connection, one can identify the cohomology group itself with the cohomology of the constant family 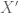 defined by the fibre at
defined by the fibre at  . However, the Hodge filtrations will not agree, but are allowed to vary within the confines imposed by Griffiths transversality. Explicitly, one can show that
. However, the Hodge filtrations will not agree, but are allowed to vary within the confines imposed by Griffiths transversality. Explicitly, one can show that
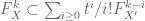 .
.
In the crystalline situation, given two smooth lifts 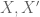 , one obtains a similar formula,
, one obtains a similar formula,
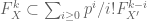 .
.
However, note that the denominators start to cancel off the powers of , once  , and this is exactly why Mazur can only get the estimate involving
, and this is exactly why Mazur can only get the estimate involving  . For a more general statement in the same vein see Ogus’ “corollary 2.5.”
. For a more general statement in the same vein see Ogus’ “corollary 2.5.”
These are all inequalities, and it is natural to ask if they are “strict”. In other words, does Griffiths transversality really happen (do these filtrations vary), and to what extent? One obvious example to bear in mind is abelian varieties, where every possible lift of the Hodge filtration corresponds to a lift (and determines it uniquely: this is Grothendieck-Messing theory). If, as the filtration lengths increase, there is enough freedom for the lifts to vary widely within the constraints imposed by transversality, then one would expect a counterexample to strong divisibility.
Ogus manages precisely this, and his example is as follows. Suppose 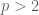 , and consider the hypersurface
, and consider the hypersurface 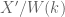 given by
given by
 .
.
Then 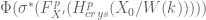 fails to lie in
fails to lie in 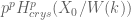 .
.
This is achieved by comparing to the Fermat hypersurface which also visibly lifts the special fibre. One can show that in fact the cohomology of this is strongly divisible, exploiting the fact the group actions in play give an explicit decomposition of the cohomology, making it easy to control. Comparing the filtration coming from this to the filtration coming from , using a careful deformation-theoretic study of these differences, Ogus deduces that the latter fails to be strongly divisible.

![\mathbb{Z}[1/N]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B1%2FN%5D&bg=ffffff&fg=545454&s=0&c=20201002)
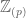
 of fields, many readers will be familiar with the usual “Galois descent” procedure giving an equivalence between (for example) affine varieties over
of fields, many readers will be familiar with the usual “Galois descent” procedure giving an equivalence between (for example) affine varieties over  and affine varieties over
and affine varieties over  with a suitable
with a suitable  action. Indeed, such extensions are finite etale, and the result is immediate from the general theory of etale descent and the “Galois isomorphism”
action. Indeed, such extensions are finite etale, and the result is immediate from the general theory of etale descent and the “Galois isomorphism” 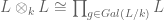 , which one can unravel and check implies that to give a
, which one can unravel and check implies that to give a  and noting that only the open index 2 subgroups give rise to degree 2 etale algebras. In the case where
and noting that only the open index 2 subgroups give rise to degree 2 etale algebras. In the case where  is profinite and imposing continuity conditions like the one we saw above, one is able to recover Galois descent theory from the finite case. However, if the extension is transcendental, it is less clear how to proceed. For example, a key obviously interesting example is when one has an object over
is profinite and imposing continuity conditions like the one we saw above, one is able to recover Galois descent theory from the finite case. However, if the extension is transcendental, it is less clear how to proceed. For example, a key obviously interesting example is when one has an object over 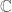 together with an action of
together with an action of  . Here
. Here  be a variety (geometrically reduced separated scheme of finite type) over a field
be a variety (geometrically reduced separated scheme of finite type) over a field  which we assume is algebraically closed (to avoid having to define “Galois”). Let
which we assume is algebraically closed (to avoid having to define “Galois”). Let  be a subfield. A descent system for
be a subfield. A descent system for  one for each
one for each  satisfying the cocycle condition
satisfying the cocycle condition 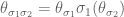 . We emphasise that such a thing is generally not the same as a descent datum. If there is a model
. We emphasise that such a thing is generally not the same as a descent datum. If there is a model 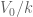 giving rise to
giving rise to  by base change, we say
by base change, we say 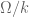 be an algebraically closed extension of infinite transcendence degree, and suppose we are given
be an algebraically closed extension of infinite transcendence degree, and suppose we are given  to
to  is effective.
is effective. such that any automorphism of
such that any automorphism of 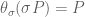 for all
for all  .
. and the condition (2) implies that the isomorphisms coming from the model and the given
and the condition (2) implies that the isomorphisms coming from the model and the given 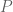 . They therefore agree by condition (1), so we have established effectivity of the restriction of
. They therefore agree by condition (1), so we have established effectivity of the restriction of 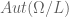 . The desired result now follows from the theorem.
. The desired result now follows from the theorem.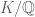 be a cubic totally real field. We wish to carefully choose a quaternion algebra
be a cubic totally real field. We wish to carefully choose a quaternion algebra 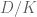 such that
such that 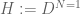 admits a symplectic representation.
admits a symplectic representation. , equipped with a natural map
, equipped with a natural map 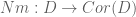 . In particular, if we can arrange for
. In particular, if we can arrange for 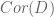 to be split, we will certainly get a natural (8-dimensional) representation of
to be split, we will certainly get a natural (8-dimensional) representation of  . By then imposing some conditions at infinity we can produce a symplectic structure on this representation, realising the resulting Shimura variety as one of Hodge type.
. By then imposing some conditions at infinity we can produce a symplectic structure on this representation, realising the resulting Shimura variety as one of Hodge type. to be ramified at any even number of places above each place of
to be ramified at any even number of places above each place of 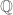 , and at two of the three places at infinity.
, and at two of the three places at infinity.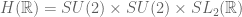 , and unravelling the construction one sees that the map
, and unravelling the construction one sees that the map 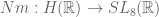 factors
factors 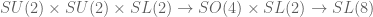 where the first map is the standard degree 2 isogeny
where the first map is the standard degree 2 isogeny 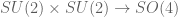 and the second is given by the natural action on
and the second is given by the natural action on 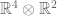 , and visibly preserves the natural symplectic pairing coming from the product of orthogonal and symplectic pairings on these two spaces. Symplectic structures descend, giving the required map
, and visibly preserves the natural symplectic pairing coming from the product of orthogonal and symplectic pairings on these two spaces. Symplectic structures descend, giving the required map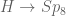 over
over 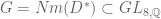 , which is an extension of the image of
, which is an extension of the image of  by
by  landing in
landing in 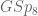 .
. to be the composite of
to be the composite of  with the map taking
with the map taking 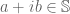 to
to  on the
on the  factor of
factor of 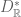 and the standard 2-dimensional embedding into the
and the standard 2-dimensional embedding into the 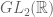 factor. It is obvious this extends to give the Siegel Shimura datum on
factor. It is obvious this extends to give the Siegel Shimura datum on  , and a connection is an additive map of sheaves
, and a connection is an additive map of sheaves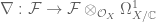
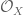 -linear map between the underlying sheaves making the obvious square commute.
-linear map between the underlying sheaves making the obvious square commute.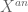 . Given an algebraic differential equation, we can analytify it and obtain an analytic differential equation:
. Given an algebraic differential equation, we can analytify it and obtain an analytic differential equation: 
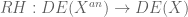 .
.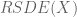 is characterised by taking a good compactification of
is characterised by taking a good compactification of 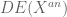 than in
than in 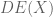 because one can write down more connections, but actually the extra freedom causes more stuff to become isomorphic, resulting in a “smaller” analytic category. Of course, one has
because one can write down more connections, but actually the extra freedom causes more stuff to become isomorphic, resulting in a “smaller” analytic category. Of course, one has 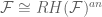 but not (unless
but not (unless 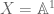 and
and  , and observe that any connection is automatically flat and determined by
, and observe that any connection is automatically flat and determined by 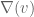
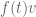 which by Leibniz is given by
which by Leibniz is given by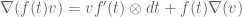 ).
).![g(t) \in \mathbb{C}[t]](https://s0.wp.com/latex.php?latex=g%28t%29+%5Cin+%5Cmathbb%7BC%7D%5Bt%5D&bg=ffffff&fg=545454&s=0&c=20201002) let us denote by
let us denote by 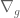 the connection taking
the connection taking  .
.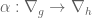 between two such differential equations. Let
between two such differential equations. Let  , and the compatibility of
, and the compatibility of  with the connections gives the relation
with the connections gives the relation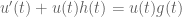 .
. must satisfy a first order differential equation, and in fact we see that up to a constant factor
must satisfy a first order differential equation, and in fact we see that up to a constant factor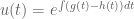
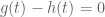 .
. , which is the unique algebraic connection with regular singularities at
, which is the unique algebraic connection with regular singularities at 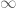 .
.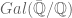 -representations from Emerton’s study of completed cohomology. For this to work, one needs Bockle’s arguments after Gouvea-Mazur and Coleman to deduce “big” R=T theorems from “small” ones which are not too difficult given the success of the original Taylor-Wiles-(Diamond?)-Kisin approach. I attach a
-representations from Emerton’s study of completed cohomology. For this to work, one needs Bockle’s arguments after Gouvea-Mazur and Coleman to deduce “big” R=T theorems from “small” ones which are not too difficult given the success of the original Taylor-Wiles-(Diamond?)-Kisin approach. I attach a 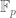 -algebra
-algebra  , a strict
, a strict  in which
in which 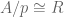 . The key fact about these rings is the following.
. The key fact about these rings is the following.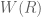 exists, and is unique up to unique isomorphism as a ring over
exists, and is unique up to unique isomorphism as a ring over  is a functor).
is a functor).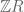 thereon. This has elements
thereon. This has elements ![\sum_i n_i[r_i]](https://s0.wp.com/latex.php?latex=%5Csum_i+n_i%5Br_i%5D&bg=ffffff&fg=545454&s=0&c=20201002) with addition as a “free
with addition as a “free 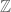 -module” and multiplication coming from the monoid structure. For example, this means that weirdly
-module” and multiplication coming from the monoid structure. For example, this means that weirdly ![[0]\not= 0](https://s0.wp.com/latex.php?latex=%5B0%5D%5Cnot%3D+0&bg=ffffff&fg=545454&s=0&c=20201002) yet (but
yet (but ![[1]=1](https://s0.wp.com/latex.php?latex=%5B1%5D%3D1&bg=ffffff&fg=545454&s=0&c=20201002) ). There is also (induced from the identity on
). There is also (induced from the identity on 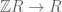 . Let
. Let 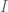 be its kernel, and form the
be its kernel, and form the 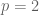 appears no harder). By taking q-expansions, one can consider the algebra of classical modular forms of level 1 (all weights and indeed mixed weights) as a subalgebra
appears no harder). By taking q-expansions, one can consider the algebra of classical modular forms of level 1 (all weights and indeed mixed weights) as a subalgebra ![\mathcal{M} \subseteq \mathbb{C}[[q]].](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BM%7D+%5Csubseteq+%5Cmathbb%7BC%7D%5B%5Bq%5D%5D.&bg=ffffff&fg=545454&s=0&c=20201002) In fact, flat base change and the construction of models for modular curves implies one can actually do this on the integral and rational levels in such a way as loses no information: one is naturally led to study
In fact, flat base change and the construction of models for modular curves implies one can actually do this on the integral and rational levels in such a way as loses no information: one is naturally led to study ![\mathcal{M}_\mathbb{Z} \subseteq \mathbb{Z}[[q]]](https://s0.wp.com/latex.php?latex=%5Cmathcal%7BM%7D_%5Cmathbb%7BZ%7D+%5Csubseteq+%5Cmathbb%7BZ%7D%5B%5Bq%5D%5D&bg=ffffff&fg=545454&s=0&c=20201002) and
and  . But now note that
. But now note that ![\mathbb{Z}[[q]]\otimes \mathbb{Q} \subset \mathbb{Z}_p[[q]][1/p]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BZ%7D%5B%5Bq%5D%5D%5Cotimes+%5Cmathbb%7BQ%7D+%5Csubset+%5Cmathbb%7BZ%7D_p%5B%5Bq%5D%5D%5B1%2Fp%5D&bg=ffffff&fg=545454&s=0&c=20201002) , a subring of
, a subring of ![\mathbb{Q}_p[[q]]](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BQ%7D_p%5B%5Bq%5D%5D&bg=ffffff&fg=545454&s=0&c=20201002) which can be equipped with the structure of a Banach algebra via the ‘sup norm’ (the distance between
which can be equipped with the structure of a Banach algebra via the ‘sup norm’ (the distance between 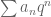 and
and  is the largest value of
is the largest value of 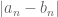 ).
).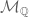 with respect to this topology, and it is this which Serre defines to be the algebra
with respect to this topology, and it is this which Serre defines to be the algebra 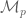 of
of  . From this one can easily attach a weight in the group
. From this one can easily attach a weight in the group 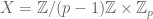 to a p-adic modular form (and since we are working at level 1, all weights arising will be even (so the subgroup
to a p-adic modular form (and since we are working at level 1, all weights arising will be even (so the subgroup 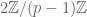 on the first factor is all that is hit). We should remark that this computation has as an input the classical theorem of Clausen-von Stadt on the denominators of Bernoulli numbers.
on the first factor is all that is hit). We should remark that this computation has as an input the classical theorem of Clausen-von Stadt on the denominators of Bernoulli numbers.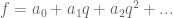 and we would like to show it’s a p-adic modular form. Maybe we can write it as a putative limit of some modular forms
and we would like to show it’s a p-adic modular form. Maybe we can write it as a putative limit of some modular forms 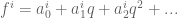 , except we only know that for all
, except we only know that for all 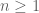 the coefficients
the coefficients  converge (but know nothing about the constant coefficients). Suppose further we also know the weights
converge (but know nothing about the constant coefficients). Suppose further we also know the weights  converge to some nonzero
converge to some nonzero 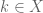 .
. 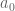 and
and  cannot be too close p-adically, where the length scale implicit in the phrase ‘too close’ is given with reference to one of the modular forms in question, so one gets a bound of the form
cannot be too close p-adically, where the length scale implicit in the phrase ‘too close’ is given with reference to one of the modular forms in question, so one gets a bound of the form 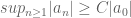 , where
, where  is some constant depending on how far
is some constant depending on how far  we learn in particular that the $a^i_0$ lie in a closed bounded subset of
we learn in particular that the $a^i_0$ lie in a closed bounded subset of  , so there is a convergent subsequence, and passing to the corresponding subsequence of modular forms we deduce that
, so there is a convergent subsequence, and passing to the corresponding subsequence of modular forms we deduce that 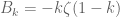 and the “sum of
and the “sum of  th powers of all divisors of
th powers of all divisors of  ” function
” function 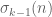 :
: .
.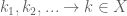 of weights that also tends to infinity in the archimedean metric, then one sees explicitly that p-adically:
of weights that also tends to infinity in the archimedean metric, then one sees explicitly that p-adically: .
. of Eisenstein series fit exactly in the situation of the above theorem, and we deduce that there is a p-adic Eisenstein series of any weight
of Eisenstein series fit exactly in the situation of the above theorem, and we deduce that there is a p-adic Eisenstein series of any weight  depends only on
depends only on 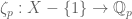 such that
such that 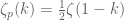 for all
for all 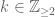 . One can check that this is exactly the p-adic zeta function constructed classically by Kubota-Leopoldt and featuring on the analytic side of the main conjecture of Iwasawa theory.
. One can check that this is exactly the p-adic zeta function constructed classically by Kubota-Leopoldt and featuring on the analytic side of the main conjecture of Iwasawa theory.